在信息爆炸的時代,我們常常會使用記事本記錄各種信息,如日志、筆記、臨時數據等。這些記事本文件通常包含結構化和非結構化的文本數據。對這些“帶文字的記事本”進行數據分析,可以有效提取有價值的信息,為決策提供支持。由于記事本數據往往格式松散、缺乏統一結構,其數據處理過程需要特定的方法和技巧。本文將介紹如何系統地對記事本數據進行數據處理與分析。
1. 數據采集與導入
數據處理的第一步是采集原始記事本文件。這些文件可能以.txt、.log、.csv(但以文本格式存儲)等格式存在。在導入數據時,需要注意文件的編碼格式(如UTF-8、GBK等),避免亂碼問題。可以使用Python的open()函數、Pandas庫的read_csv()(指定分隔符)或專門處理文本的工具進行讀取。對于大量文件,可以編寫腳本批量導入。
2. 數據清洗與預處理
記事本數據通常包含大量噪聲,清洗是關鍵步驟:
- 去除無關內容:刪除空白行、廣告文本、重復條目等。
- 標準化格式:統一日期、時間、數字的格式,例如將“2023-1-1”轉換為“2023-01-01”。
- 處理缺失值:識別并填充或刪除缺失的數據字段。
- 文本清理:使用正則表達式去除特殊字符、標點符號,或進行分詞處理(針對中文可用jieba庫)。
3. 數據結構化
記事本數據常為非結構化文本,需要轉換為結構化數據以便分析:
- 定義字段:根據內容識別關鍵字段,如時間、地點、人物、事件等。
- 使用分隔符:如果數據中有固定分隔符(如逗號、制表符),可將其轉換為表格形式。
- 自然語言處理(NLP):對于自由文本,應用NLP技術(如命名實體識別、情感分析)提取結構化信息。例如,從日志中提取錯誤類型和發生時間。
4. 數據分析與挖掘
一旦數據被結構化,即可進行深入分析:
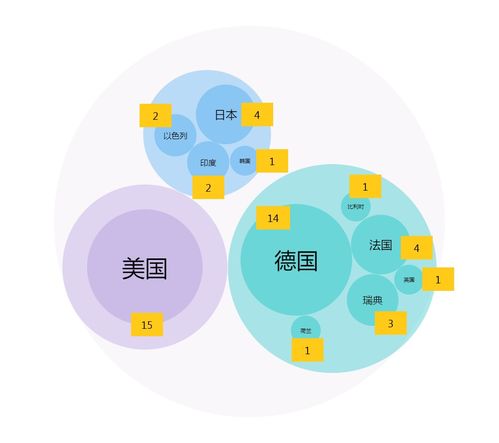
- 描述性分析:統計詞頻、時間分布、關鍵指標匯總等。例如,分析記事本中特定關鍵詞的出現頻率。
- 趨勢分析:識別數據隨時間的變化模式,如用戶活動高峰時段。
- 關聯分析:發現不同字段之間的關系,比如某些事件常同時發生。
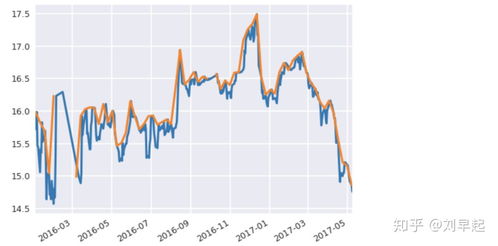
- 可視化:使用圖表(如折線圖、柱狀圖、詞云)直觀展示分析結果,幫助快速洞察。
5. 工具與實例
常用工具包括Python(Pandas、NumPy、正則表達式)、R、Excel以及文本編輯器(如Notepad++)。例如,一個簡單的Python腳本可以自動化清洗日志文件:讀取文件、過濾錯誤行、提取時間戳和錯誤碼,并生成統計報告。通過結合這些工具,即使是雜亂的記事本數據也能轉化為清晰的見解。
處理帶文字的記事本數據是一個從混沌到有序的過程。通過系統的采集、清洗、結構化和分析,我們可以將這些日常記錄轉化為有價值的信息資產,助力個人或企業優化流程、發現問題并提升效率。隨著人工智能技術的發展,未來這類數據處理將更加智能化和自動化。